有意思的问题
当第一次接触 RisingWave 或者流数据库时,不同背景的读者往往会问出很多有意思的问题。在本文中,我们总结了一下常见的问题。
RisingWave 是否可以平替 Flink SQL?
RisingWave 本身能力是 Flink SQL的超集。从能力角度来讲,Flink SQL 的用户完全可以较为容易的迁移到 RisingWave 上。Flink SQL 也不具备 RisingWave 的一些功能,例如层级物化视图等。
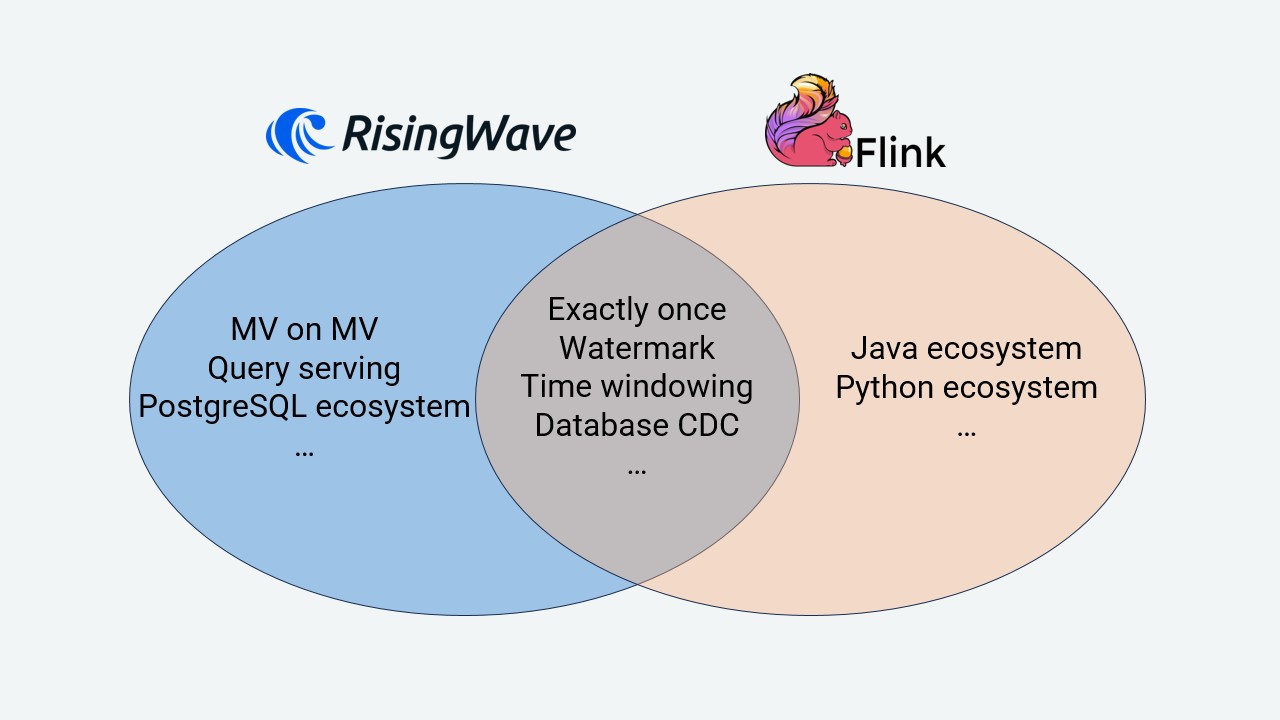
RisingWave 使用的是 PostgreSQL 语法,相信学习与使用门槛要远低于 Flink SQL。但要注意的是,RisingWave 与 Flink SQL 在语法上仍然有一些细微差别,因此用户还是可能需要对部分查询进行改写。
RisingWave 是否是流批一体系统?
“流批一体”这个名词最早是用来描述 Apache Spark、Apache Flink 这样的计算平台,而非数据库。但如果我们将这个概念对应到数据库中,那么流处理就是对新插入的数据进行连续不断的增量计算,而批处理就是对已经存储的数据进行随机批量计算。RisingWave 很显然能够同时支持流处理与批处理。
需要注意的是,RisingWave 的强项是流处理。在存储格式方面,由于 RisingWave 采用的是行存,因此 RisingWave 更加适合对已存储的数据做点查,而并非全表扫描。因此,如果用户对随机全表分析查询有大量需求,那么我们更加推荐用户使用 ClickHouse、Apache Doris 等实时分析型数据库。
RisingWave 支持事务处理吗?
RisingWave 不支持读写事务处理,但其支持只读事务。RisingWave 并不能替代 PostgreSQL 做事务处理。这一设计主要是因为在真实场景中,用户一般都需要使用独占的事务型数据库以支持在线业务。如果在同一数据库内同时支持事务处理与流处理,将使得数据库的负载处理变得极为复杂,很难达到两方面最优。
在生产中,使用 RisingWave 的最佳实践是将 RisingWave 放在事务型数据库的下游。RisingWave 通过 CDC 从事务型数据库中读取已经被序列化过的数据。
RisingWave 中的表存储为什么使用行存?
RisingWave 使用了相同的存储系统来支持内部状态管理与数据存储。在内部状态管理中,各类算子的存储均更适合使用行存,而在数据存储中,由于用户更有可能偏向于进行随机点查,因此也是使用行存更加合适。未来 RisingWave 有可能会周期性将行存转换成列存,以更好的支持随机分析类查询。
流数据库是否可以被认为是流处理引擎+数据库组合?
流数据库不是简单的流处理引擎(如 Apache Flink)与数据库(如 PostgreSQL)的拼接。主要原因包括:
- 从设计来讲,流数据库使用同一套存储进行内部状态管理与结果存储与结果随机查询。独立的数据库很显然不适合做内部状态存储,因为频繁跨系统数据访问会造成巨大开销,对流处理系统这类对延迟敏感的系统来说并不可取。事实上,早年的分布式流处理引擎,如 Apache Storm、Apache S4 等,均试过这条道路,但这种设计并没有成功延续下来;
- 从功能上来讲,流数据库的核心功能之一是层级物化视图。想要模拟出层级物化视图,用户需要在流处理引擎与数据库之外,再引入如 Kafka 等消息队列,来实现物化视图与物化视图之间的消息传递;
- 从实现来讲,想要在多个独立系统之间保证一致性,则需要建立一套框架保证即便在某一系统宕机之后,不同系统之间仍能够做到一致。实现这一框架显然需要付出更多的工程投入;
- 从运维来讲,很显然运维多套不同的系统会带来非常高的运维成本;
- 从用户体验来讲,用户使用多套系统的体验与使用一套系统的体验有相当大的差距。
流数据库与实时分析数据库有什么不同?
主流的流数据库包括了 RisingWave、KsqlDB 等;主流的实时分析数据库包括了 ClickHouse、Apache Doris 等。
从应用上来讲,流数据库主要被用来做监控、报警、实时动态报表等业务;实时分析数据库主要被用来做交互式报表等业务。与此同时,流数据库也被用来做流式 ETL 操作。
从功能上来讲,无论是在流数据库还是在实时分析数据库中,用户均可以通过物化视图支持预定义查询,也可以直接发送随机查询。然而,流数据库的强项在支持预定义查询,而实时分析数据库的强项在于支持随机查询。
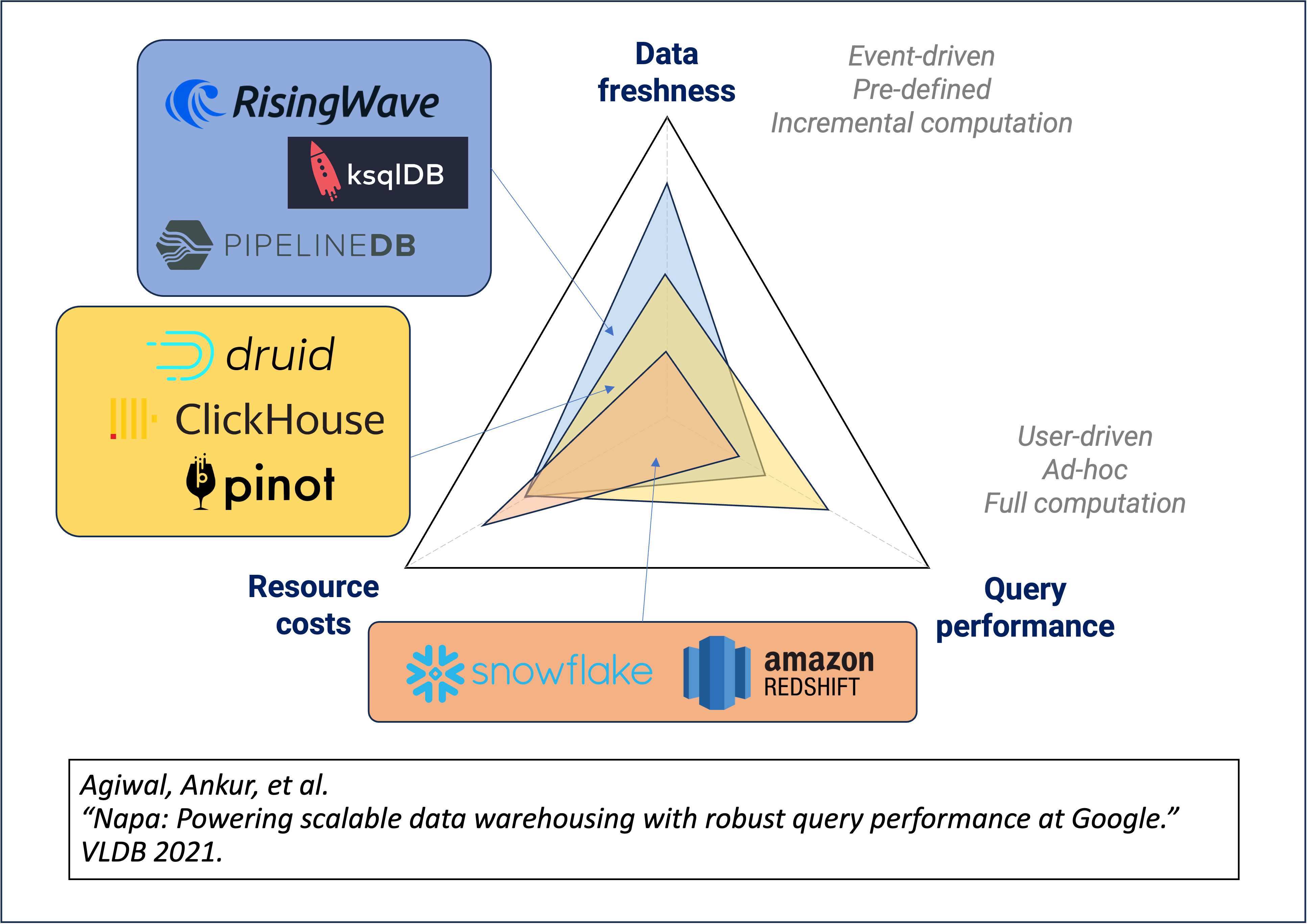
从设计上来讲,流数据库与实时分析数据库优化的方向截然不同。在 Napa 论文中,Google 的工程师提出了系统的权衡三角,即任何一个系统,只能在:
- 结果新鲜度
- 随机查询性能
- 资源成本
三者中优化两项,而并不能同时优化所有方向。
假设资源成本固定,那么流数据库本质是在优化结果新鲜度,而实时分析数据库本质是在优化随机查询性能。下图展示了流数据库、OLAP 数据库、数据仓库三者之间在设计方面的取舍。
流数据库与实时数据库的物化视图有什么不同?
由于流数据库与实时数据库侧重点不同,两者间的物化视图看似相同,但实际差别巨大。
在如 RisingWave 等为代表的流数据库中,物化视图是核心能力。流数据中的物化视图需要呈现出流处理之后得到的一致的、新鲜的计算结果,而在如 ClickHouse 等为代表的实时分析数据库中,物化视图为辅助能力。实时分析数据库经常使用的是“尽力而为” (best effort)方式来更新物化视图。于此同时,流数据库中的物化视图还实现了流处理的各种高级语义。
总结一下,RisingWave 等流数据库中的物化视图具有以下几个重要特征:
实时性:不少数据库使用异步方式更新物化视图,或者要求用户手动更新物化视图。而 RisingWave 上的物化视图使用同步方式更新,用户永远可以查询到最新鲜的结果。即便是对于带有 join、windowing 等复杂查询,RisingWave 也能够进行高效同步处理,保证物化视图新鲜度;
一致性:一些数据库仅提供最终一致性的物化视图,也就是说,用户看到的物化视图上的结果只是近似结果,或者是带有错误的结果。尤其是当用户创建多个物化视图时,由于每个物化视图刷新策略不同,用户很难在跨物化视图之间看到一致性结果。而 RisingWave 的物化视图是一致性的,哪怕访问多个物化视图,用户看到的结果永远是正确的,而不会看到不一致的结果;
高可用:RisingWave 持久化物化视图,并设置高频率检查点保证快速故障恢复。当搭载 RisingWave 的物理节点宕机时, RisingWave 可以实现秒级恢复,并且在秒级将计算结果更新至最新状态;
高并发:RisingWave 支持高并发随机查询。由于 RisingWave 将数据实时持久化在远端对象存储中,用户可以根据负载动态配置查询节点数量,更高效的支撑业务需求。
流处理语义:在流计算领域里,用户可以使用高阶语法,如时间窗口、水位线等,对数据流进行处理。而传统数据库并不带有这些语义,因此往往用户需要依赖外部系统处理这些语义。RisingWave 是流处理系统,自带各种复杂流处理语义,并可以让用户用 SQL 语句来进行操作。
资源隔离:物化视图是连续不断的流计算,会占用到大量计算资源。为避免物化视图计算干扰到其他计算,一些用户会将 OLTP 或者 OLAP 数据库中的物化视图功能转移到 RisingWave 中处理,从而实现资源隔离。